
Основную техническую часть настройки при работе с контекстной рекламой составляет сбор ключевых слов – семантического ядра. Собрать вручную полностью проработанную и качественную семантику для поисковой рекламы это очень сложно и долго. Гораздо удобнее и быстрее делать сбор семантического ядра в Key Collector.
Стоимость Кей Коллектора около 2 тыс. рублей. Также есть бесплатный аналог СловоЁБ, но с сильно урезанным функционалом (его мало). Словоёб скорее подойдёт вам для знакомства с программой, в любом случае я рекомендую обязательно покупать платную версию.
Если размышляете над покупкой платной версии программы, то она однозначно стоит своих денег. Даже малая часть её функций значительно облегчает работу и ускоряет процесс, прочитав статью вы это поймёте.
СОДЕРЖАНИЕ
Маски ключевых слов
Итак, начнём. Первым делом для настройки нужно собрать маски ключевых слов. Что такое «маска» в семантическом ядре?
Маска ключевых слов – это ключевое слово, которое не может быть уменьшено без потери смысла. Проще говоря, это 2-3-ёх словная фраза, характеризующая вашу тематику, которая включает в себя другие вложенные ключевые запросы. Посмотрите на пример ниже из сервиса Yandex.Wordstat, всё сразу станет понятно.
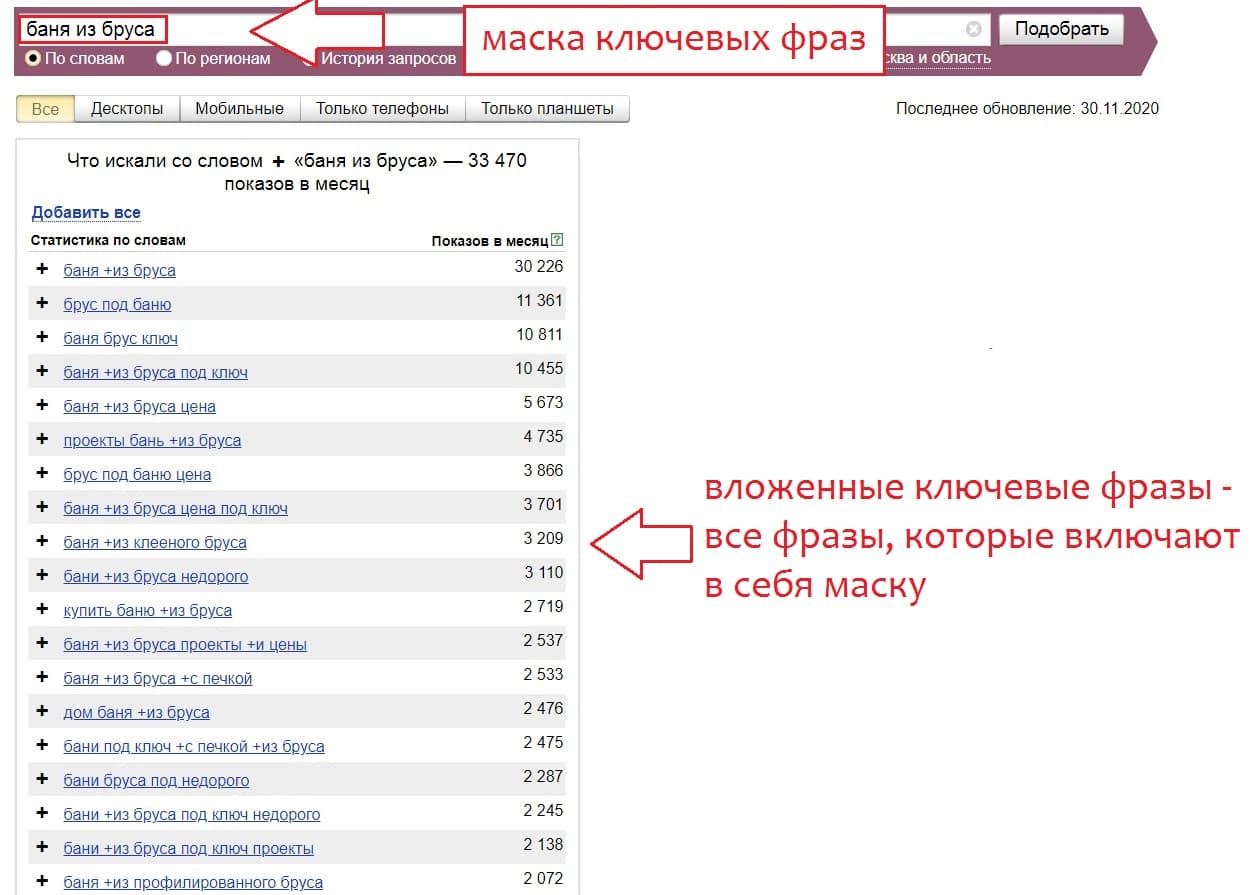
Наша первая задача – собрать максимальное количество целевых масок (баня из бруса, купить баню, брусовая баня и т.п.). Это мы делаем для того, чтобы потом загрузить маски в Key Сollector, который автоматом пробьет их в Яндекс Вордстат и соберёт все вложенные запросы.
Где брать маски? Собственная голова, рабочий сленг, форумы, сайты по тематике и сайты конкурентов и т.п.
К слову «брусовая баня» и «баня из бруса» это разные маски, нужно прорабатывать все словоформы. Система объединяет лишь падежи и числа (множественное или единственное).
Также, кроме масок, ещё желательно сразу собрать самые основные минус-слова, чтобы потом было проще чистить семантическое ядро.
После того как вы собрали все маски ключевых фраз и основные минус слова, открываем программу Кей Коллектор и делаем её настройку.
Настройка Key Сollector
Предварительно для программы нужно создать новый аккаунт яндекса. Чтобы добавить его в программу, желательно не использовать свой постоянный аккаунт, а создать для этого отдельный именно для этой цели.
Вписываете логин и пароль аккаунта в настройках во вкладке Yandex.Direct.
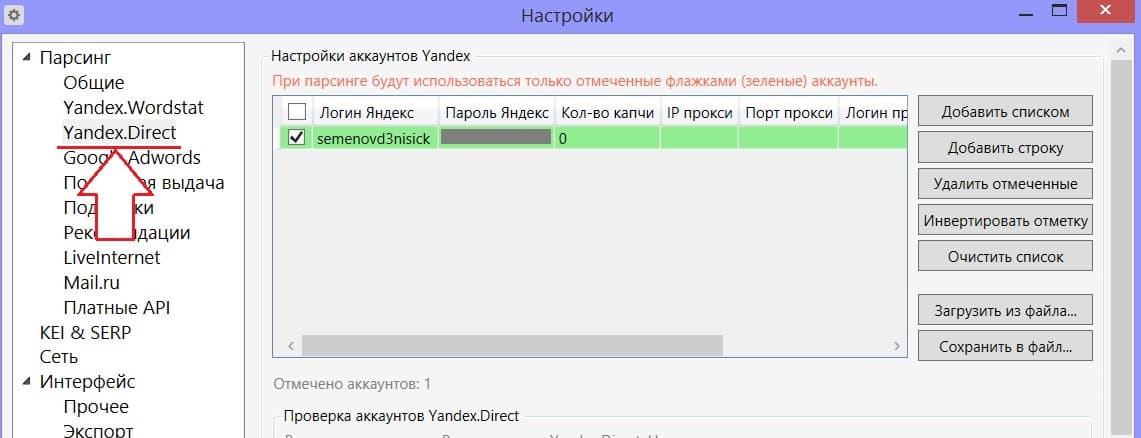
Далее делаете настройки как показано на скриншоте, во вкладе Yandex.Wordstat.

Теперь кликаем по кнопке «создать проект» и настраиваем регион сбора ключевых слов. С настройками всё, теперь приступаем к самому сбору ключевых слов (парсингу).
Интерфейс Key Collector
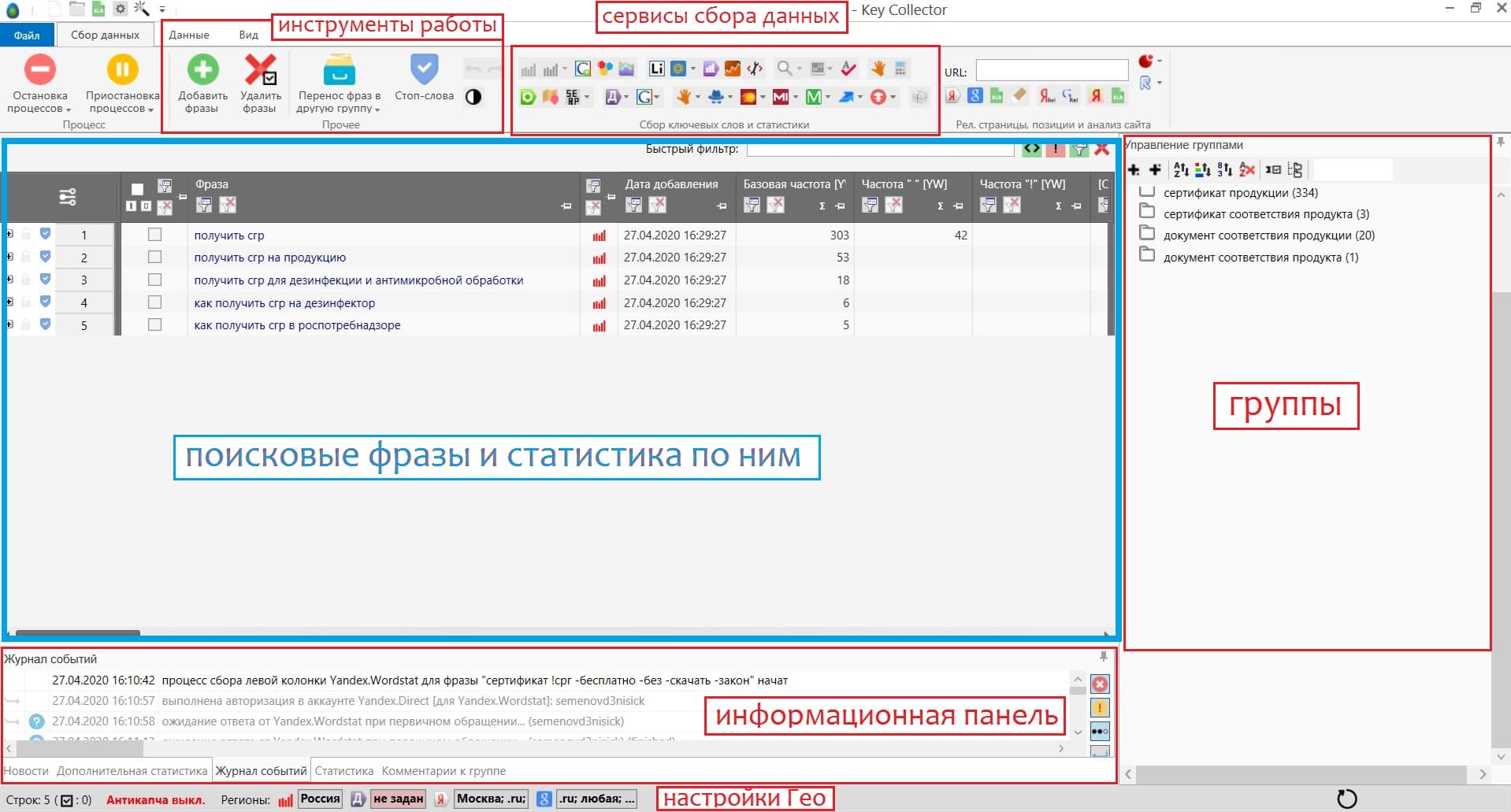
- Инструменты работы. Здесь находятся все необходимые для работы функции. Добавление фраз, удаление, перенос, группировка и т.д.
- Сервисы сбора данных. В этой панели имеются такие инструменты как: поисковые подсказки, сбор ключевых фраз из левой колонки Wordstat, сбор статистики Яндекс Директ, сбор частот из Вордстат, сбор ключевых фраз из Google Adwords и многое другое.
- Поисковые фразы и статистика по ним. В этой части интерфейса находятся поисковые запросы, которые собрала программа. Также там вся необходимая статистика (разные виды частотности, сезонность, конкуретность и другие).
- Группы. В этой области происходит управление группами, которые будут созданы при сборе ключевых слов. Таким образом мы можем группировать ключевые фразы сразу в Key Collector, что очень удобно.
- Информационная панель. В этой области находятся уведомления о работе, сбоях программы и много другой информации.
Сбор ключевых фраз (парсинг)
Добавляем раннее собранные основные минус-фразы. Я добавляю их ещё до парсинга, чтобы потом было проще чистить семантику.
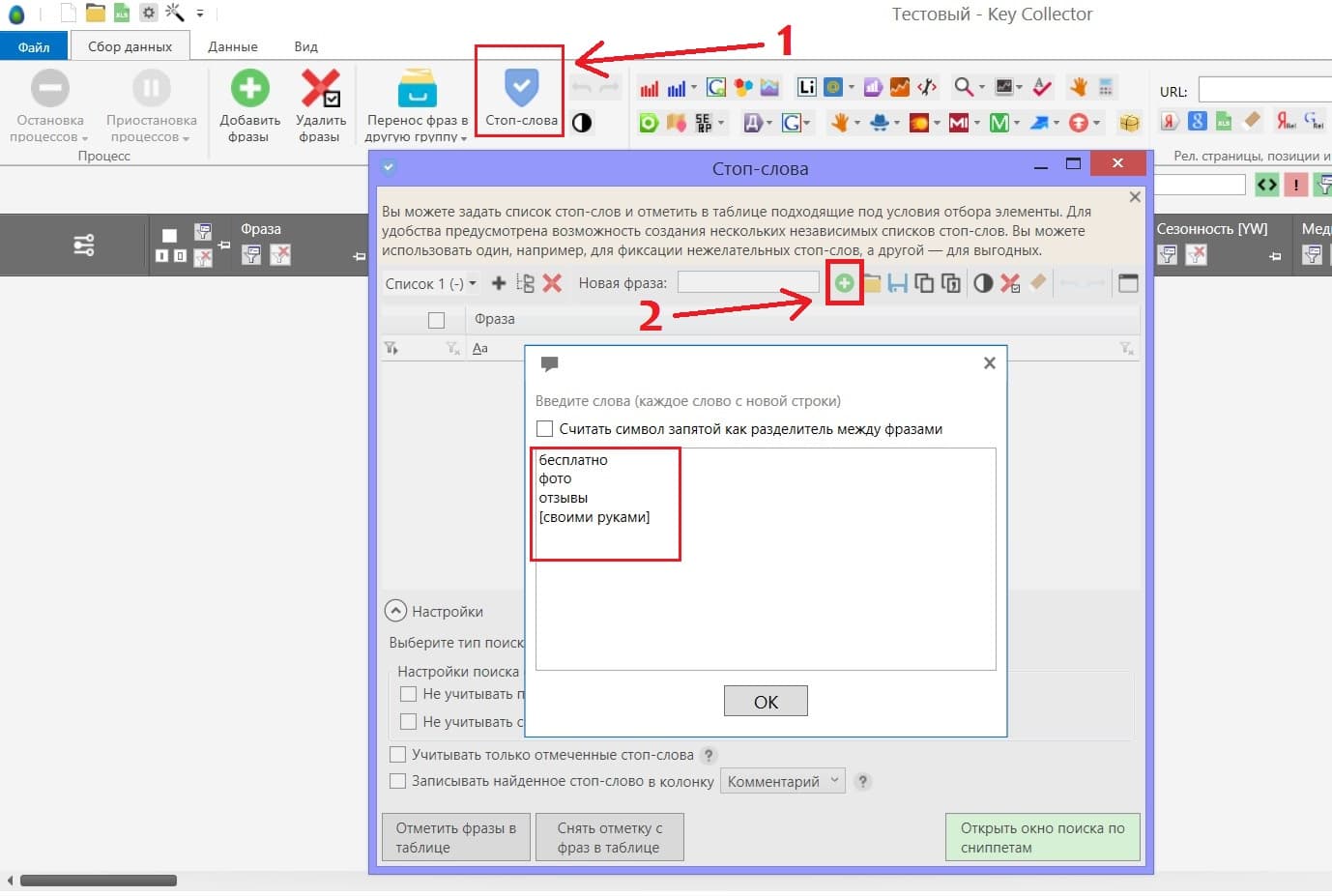
Заливаем маски ключевых слов, которые мы будем парсить и жмём “начать сбор”.
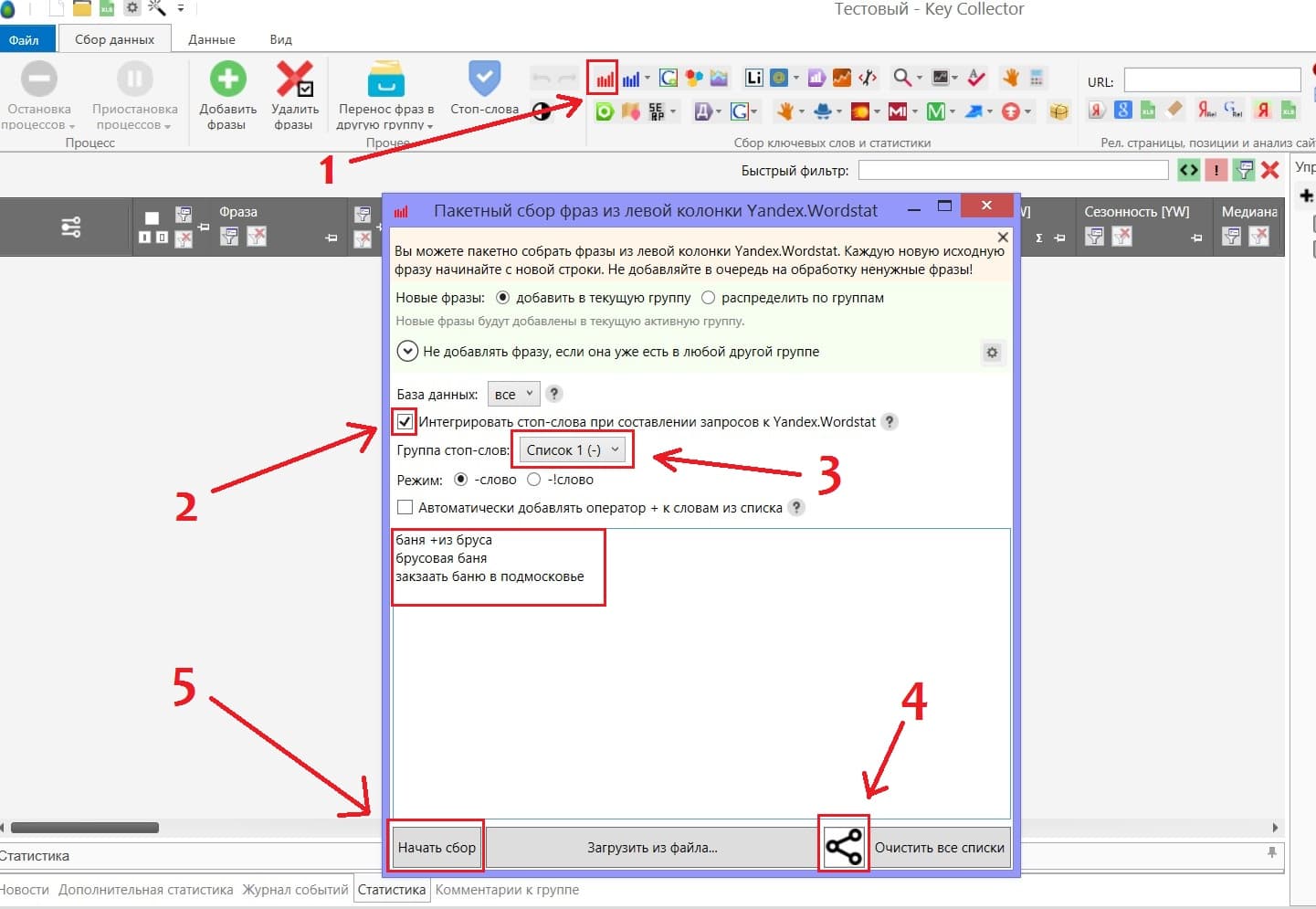
Всё, теперь отдыхаем или занимаемся другими делами, ждём пока соберутся поисковые запросы с базовой частотностью. После того, как собралась базовая частотность, ещё нужно собрать закавыченную частотность.
Зачем?
Базовая частотность фразы включает в себя другие ключевые запросы, в составе которых есть эта фраза. Запутанно… может быть. Вот условный пример для понимания.
Есть фраза Купить машину – 200 (базовая частотность)
Другие запросы, в состав которых входит фраза Купить машину
Купить машину недорого – 50
Купить поддержанную машину – 40
Куплю машину за 500 тыс. – 80
Что это значит?
Сам запрос Купить машину, именно в такой формулировке и без других слов, имеет частотность 200 – 50 – 40 – 80= 30
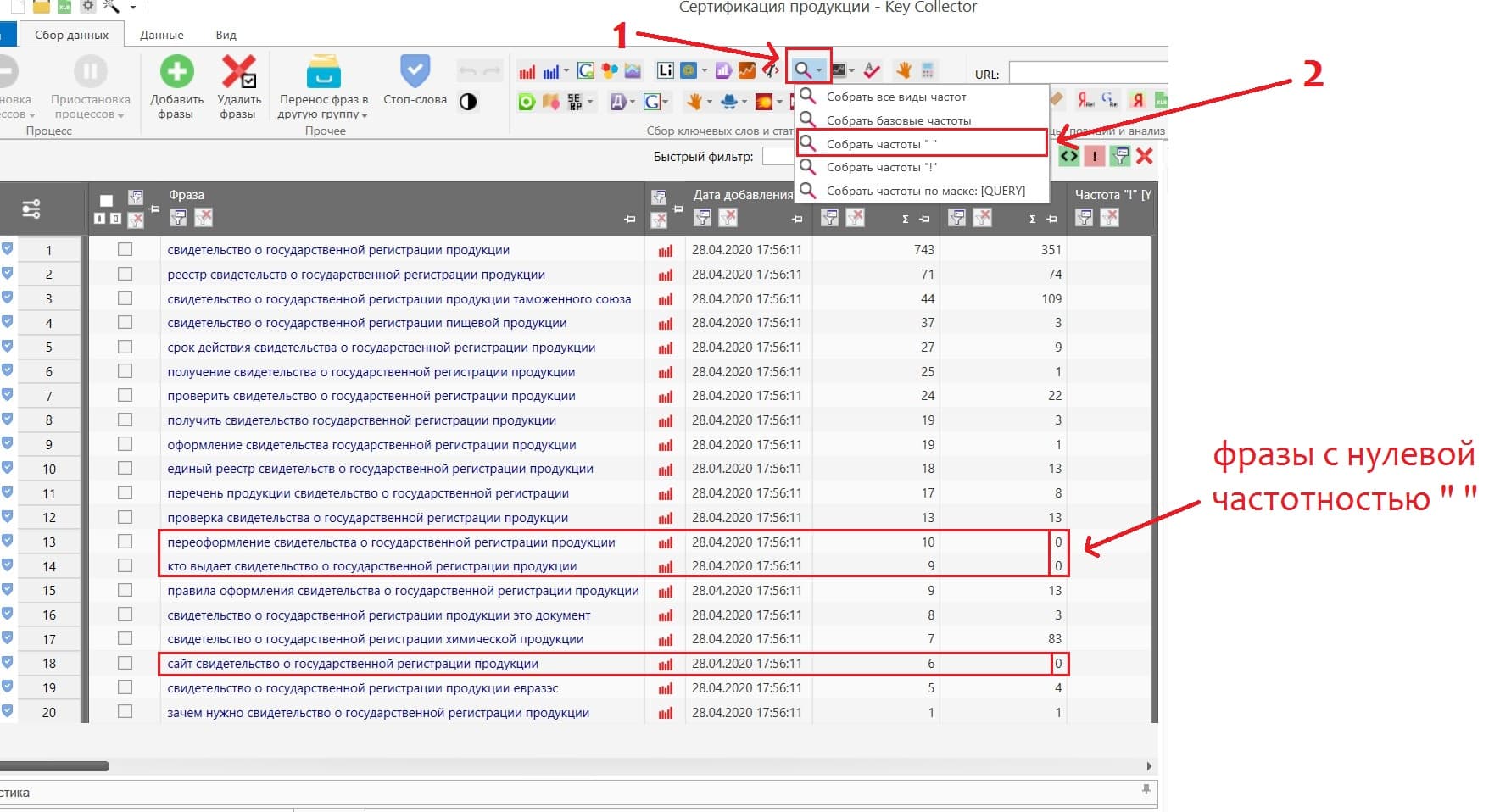
Когда мы собираем частотность «фразы» в кавычках , мы как раз таки собираем частотность конкретно этой фразы, без других фраз вложенных в неё. Если фраза с частотностью в кавычках имеет нулевую частотность, значит фразу конкретно в такой формулировке никто не вводит. Такие “нулевые” фразы нам не нужны, поэтому мы их удаляем.
Делаем фильтрацию по частотности в кавычках и удаляем фразы частотностью равной нулю.
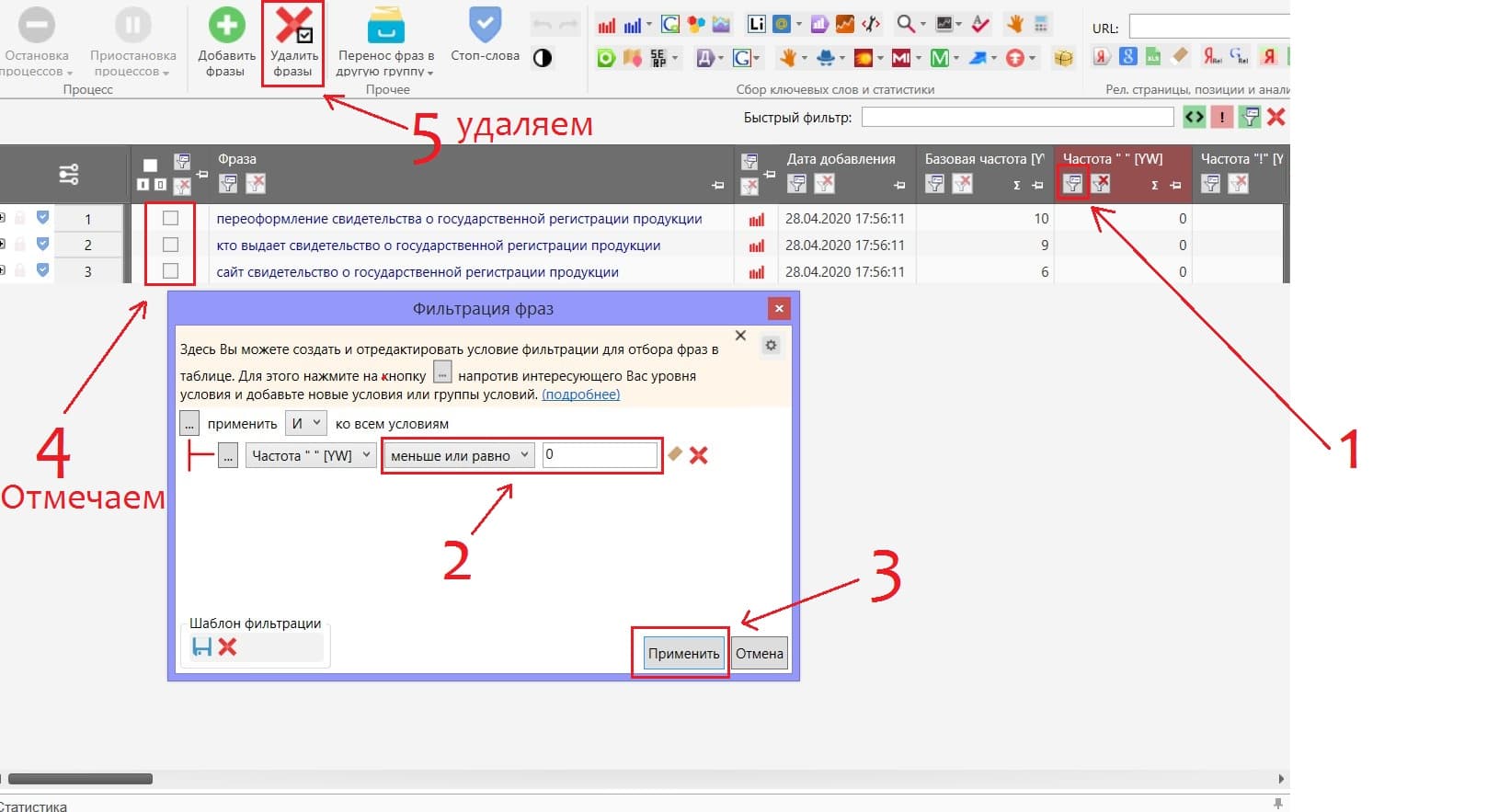
После удаления снимаем фильтр в том же окошке фильтрации и приступаем к чистке запросов, сделать это быстро можно через функции «Анализ неявных дублей» и «Анализ групп».
Чистка семантического ядра и сбор минус-слов в Key Collector
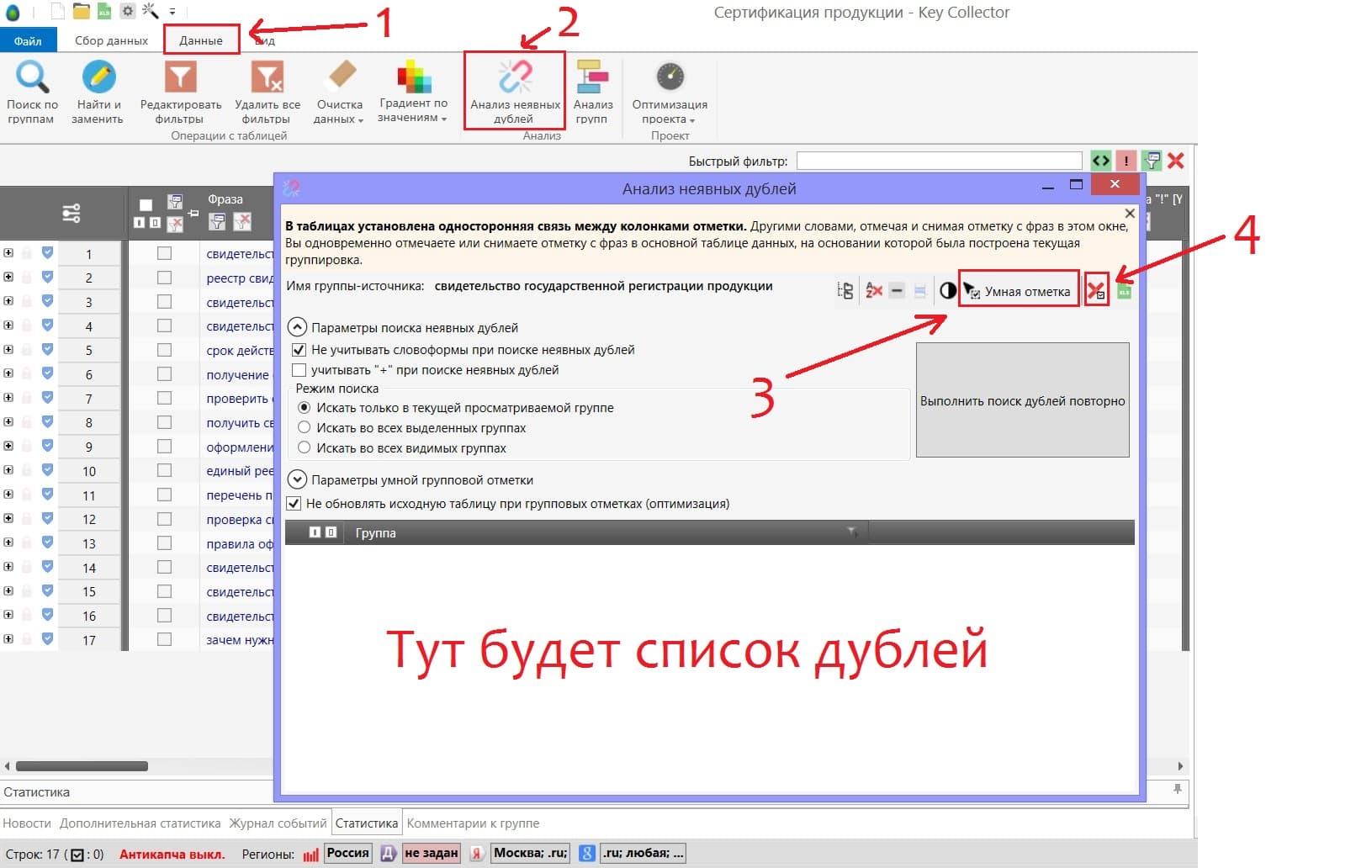
1. Чистка дублей ключевых фраз.
Для рекламной системы Яндекса фразы «купить машину недорого» и «купить недорого машину» это одно и то же, по сути это дубли с разным порядком слов. Тут всё просто, делаете как показано на скриншоте и удаляете дубли.
2. Чистка ключевых фраз и сбор минус-слов
Удобнее всего собирать минус-слова и одновременно чистить семантику через функцию «Анализ групп». Но перед этим желательно объединить все группы в одну, чтобы не вычищать группы по одной, а почистить все сразу.
Зажимаете клавишу «Shift» и кликаете по первой и последней группе, тем самым выделяете все группы, после чего нажимаете на кнопку объединения групп (3).
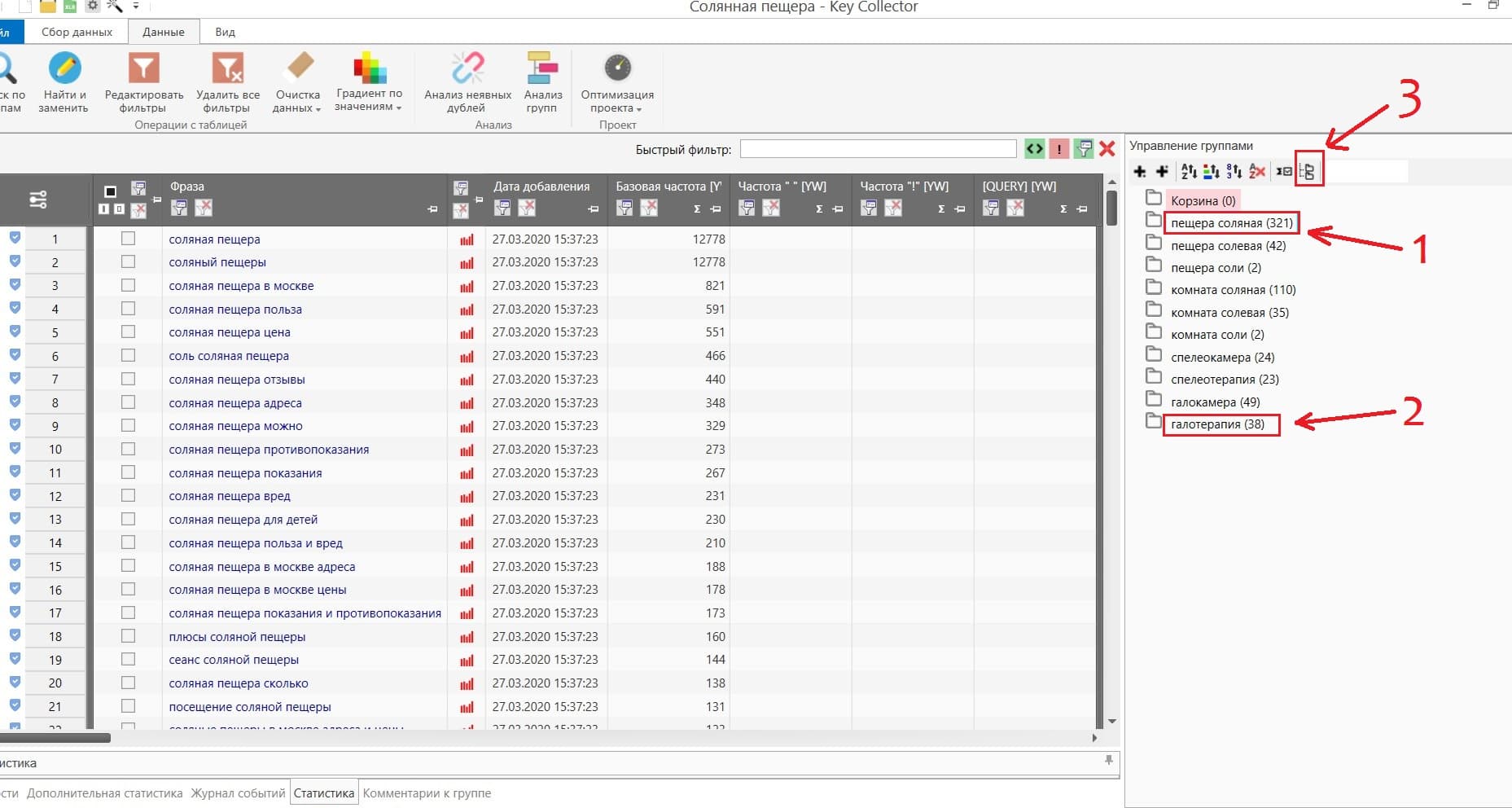
Далее заходите в «Анализ групп» (1) и отмечаете слова, которые делают запрос не подходящим для вас (2). Нажимаете правую кнопку мыши и добавляете их в список минус-слов.
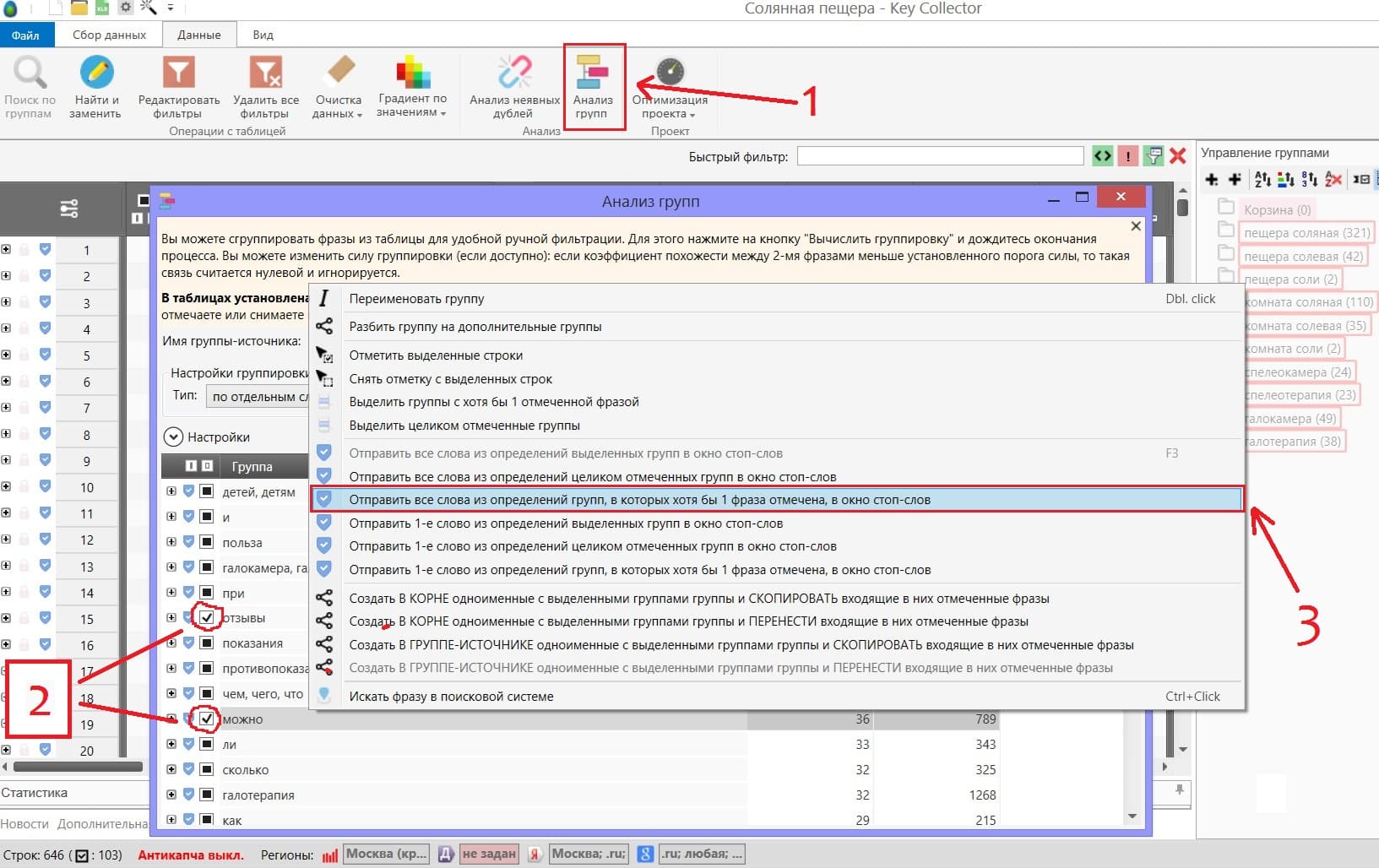
После всего вышеперечисленного отмеченные слова улетает в список минус-слов. А все фразы, содержащие выбранные минус-слова, автоматически отмечаются в основном списке фраз, чтобы потом мы могли быстро их удалить одним кликом по кнопке «удалить фразы».
Группировка семантического ядра в Key Collector
Теперь семантическое ядро почищено и собраны минус-слова. Далее нужно сделать группировку ключевых фраз. Для этого снова открываете «Анализ групп» и через фильтр в нём находите запросы, которые можно выделить в отдельные группы.
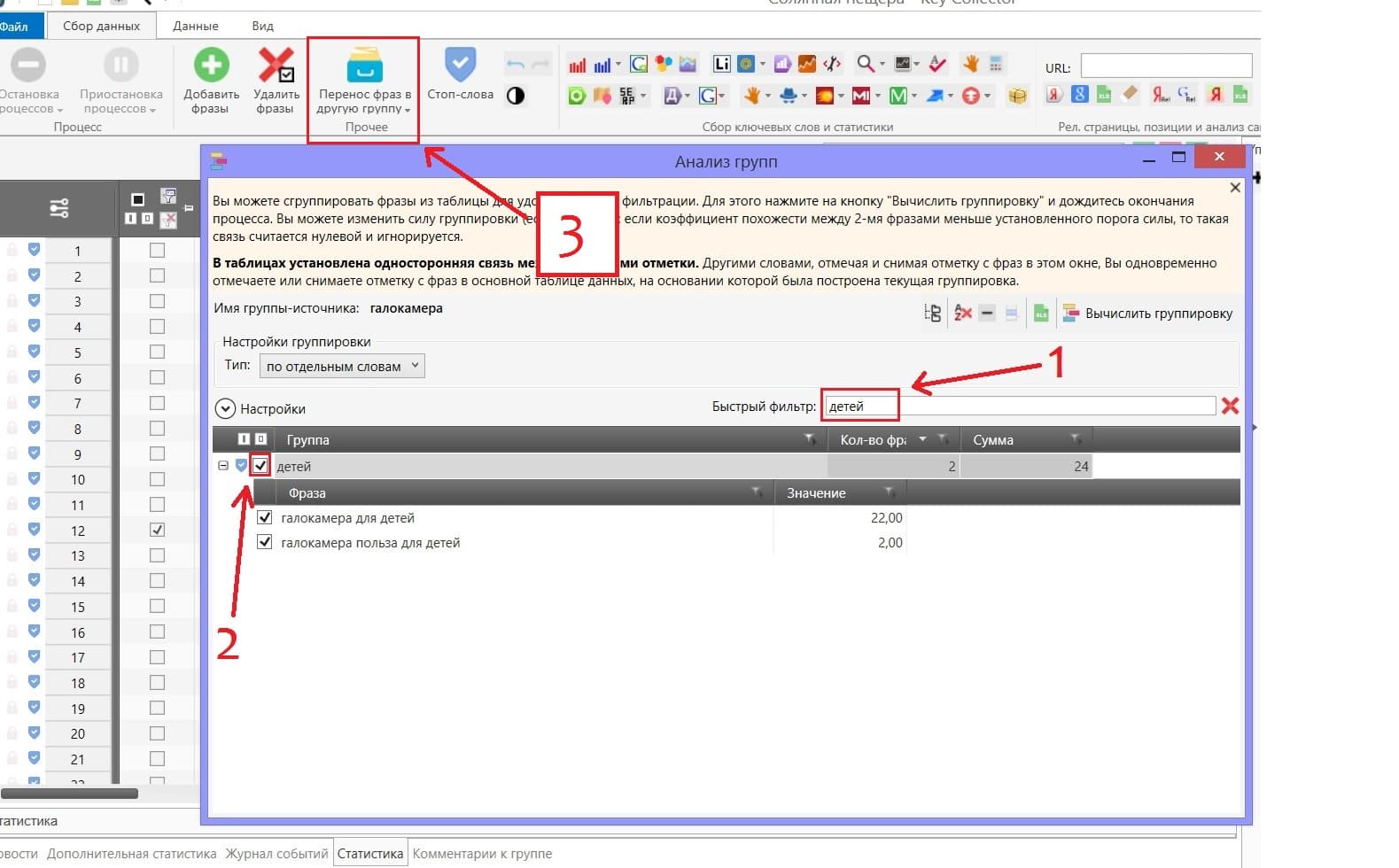
После того как отметили фразы, делаете перенос фраз в новую группу с понятным для вас названием.
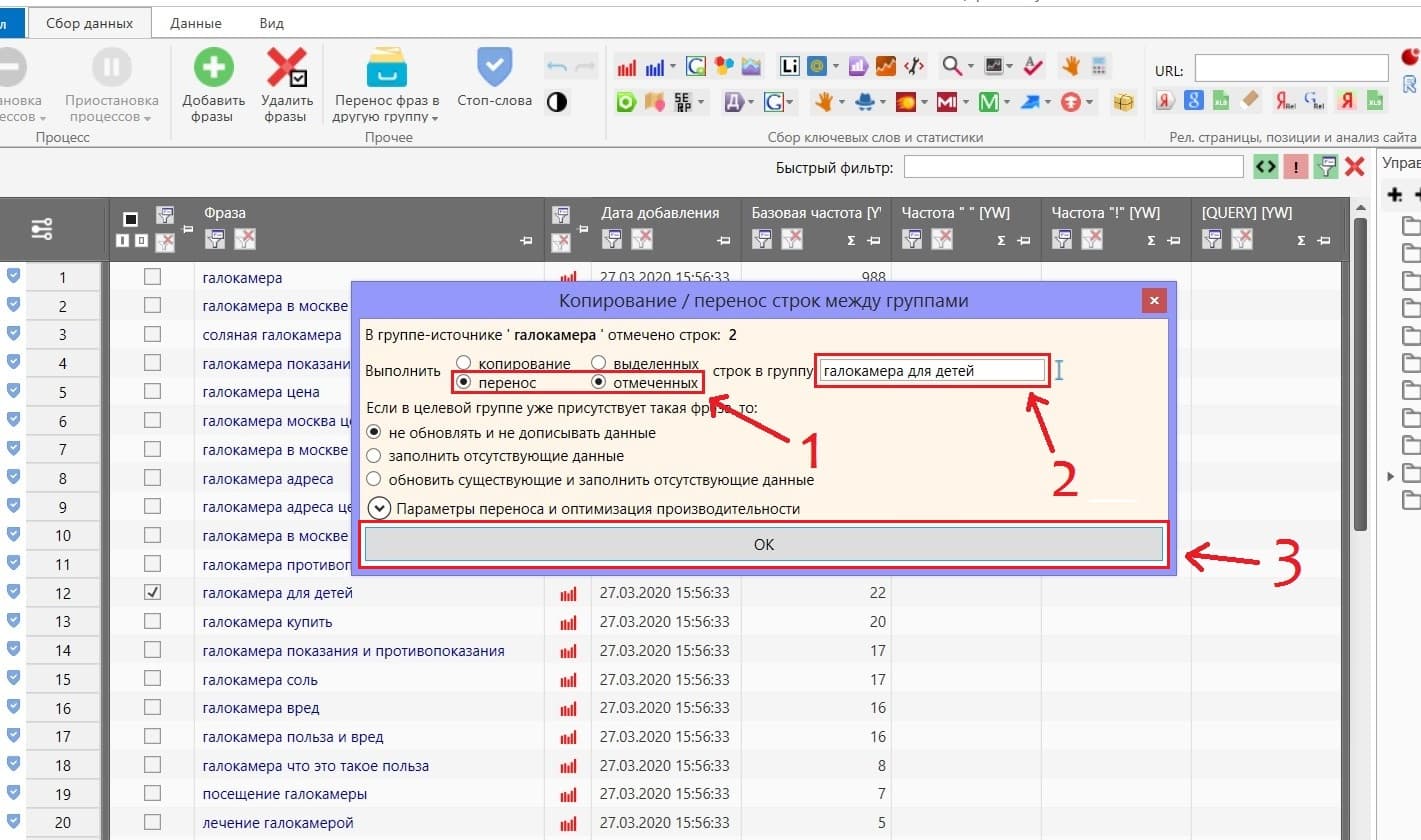
На выходе получаем собранное, вычищенное и сгруппированное семантическое ядро. Получается конечно не идеально, по мелочи руками потом всё равно придётся доделывать. Но тем не менее, Key Collector значительно экономит силы и время.






1 comment
Хорошая статья.
Я по ней составил ТЗ и заказал семантику на https://kwork.ru/categories/keywords?ref=721199 Как будет готова, начну работу над статьями